2026世界杯赛事竞猜中国官网 面壁智能BitCPM-CANN: 端侧AI的内存立异

大模子决定了“脑容量”,界说了模子的知识上限与智能天花板。
低比特时期,则是让大模子“小而强”的魔法,它重新陈列了每一个“脑细胞”的密度。这条路指向两个明确的标的:要么在有限的内存与显存资源下,塞进参数鸿沟更大的模子;要么让相同大小的模子,跑得更快、更省电。
低比特模子一直处于小众赛谈,直到本年内存价钱一年涨了5倍,倒逼通盘大模子行业寻求性价比更高的落地处理有筹画。
而早在2024年下半年,面壁智能就启动押注2-bit及以下的时期道路。彼时,面壁智能AI Infra团队在检会时不雅察到,从BF16到INT4(从高精度到底精度),模子智商耗损极小,讲解“甘好意思点”一定在更低处。
基于此,他们在那时造成了两个“反共鸣”:更低比特的模子,能赢得更高的知识密度;内存是模子行业最稀缺的资源,改日一定会变得越来越值钱。
带着这么的判断,面壁智能在GPU上率先考证了BitCPM系列。到本年,他们将这套方法论完满迁徙到了华为昇腾,端到端跑通了国产算力平台的1.58-bit检会。

测试数据浮现,比较传统BF16精度,BitCPM-CANN在推理阶段开释约6倍显存空间,同期将模子智商保留率督察在90%–97.2%。这意味着,同等模子智商在末端运行,只需昔时1/6的内存。
1.58-bit的极限挑战
“1.58-bit是时期极限考证的探针”。
面壁智能AI Infra时期认真东谈主、清华大学预计机系高性能所的水木学者博士后李宇轩向光子星球解释,开源发布最顶点的1.58-bit,筹画是为了考证极低位宽量化感知检会之路能否走通。

“1.58-bit是保证检会厚实、模子智商不坍塌的最低位宽条目。淌若这齐能得胜检会并保捏高智商,那么2-bit、4-bit、8-bit等更宽松的低比特有筹画当然更容易已毕,且成果更好”,这是一种取法乎上,仅得乎中的时期战术,即先攻克最难的点,然后再向下兼容。
如何赢得参数更小却更强的模子?行业中传统的解法是PTQ(后检会量化),即先用高精度如BF16完成模子检会,再将其权重压缩至INT8或INT4。
INT4是一种4位整数精度,比较BF16节约4倍内存,是当今低比特量化的“实用基准线”,而1.58-bit则是糟塌这条线,向极限压缩进一步靠近的探索。
这现实是一种以精度换内存的作念法,压缩越狠,性能耗损越大。就好比把一册写好的名著,压缩成口袋书,每个字只可用原来4/1的墨水写,限制是笔迹无极、内容丢失,有的所在以至看不懂。
恰是看到了PTQ的短处,面壁智能在检会上汲取了先作念QAT(量化感知检会)、再蒸馏的有筹画。李宇轩暗意,这个有筹画的中枢是既能厚实经管,又能保留全精度智商。这十分于作家最初就知谈要被制作成口袋书,成功用更爽快的言语抒发换取的内容,是以压缩后依然显露可读。
以前咱们合计,位宽越大、精度越高,模子就越贤慧。但面壁智能的推行讲授,首要的不是每个参数占多地面方,而是占的每一寸所在装了些许知识。低比特检会不再是,为了省内存而纵脱精度的和洽,而是一种全新的念念路:用最少的资源,承载最高的知识密度。
笔据BitCPM-CANN与同尺寸MiniCPM-4全精度模子家眷在学问、阅读意会、学科知识、数学与推理等11项任务上的1:1性能对照。
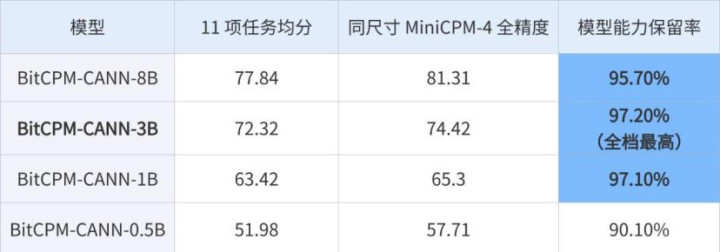
BitCPM-CANN三个尺寸模子的智商保留率达到95.7%-97.2%,即使是智商保留最弱的0.5B,保留率也达到了90%以上,险些保留住来蓝本大模子的智商。
咱们来简陋算笔账,相同一个8B大小的模子,用传统BF16步地存,光权重就要吃掉16GB空间,庸俗手机根底装不下。但用1.58-bit步地存,开释6倍显存占有空间,所占大小手机差未几十分于一部完满的高清电影。
李宇轩告诉咱们,改日他们将进行更抽象化的数据处理,将0.5B档的模子智商保留率栽培至95%。同期勾通MoE架构,诓骗寥落巨匠扩张容量上限,60B参数的超大模子有望装来源机。
跑出一条国产低比特之路
内存价钱暴涨,正在倒逼行业算明晰经济账。
公开信息浮现,2026年DDR5内存价钱暴涨数倍,32G条从年头的500元涨至超4000元,HBM更是天价。
这让自身就对价钱敏锐的端侧厂商堕入了两难境地。有手机厂商告诉咱们,用户期待更强的AI智商,但内存加价3-5倍后,若督察原内存升级节拍,价钱翻倍;不涨成就则体验倒退,用户不买单;加价又怕丢失市集,部分旗舰机型照旧被动足履实地。
要处理上头的长途,国产替代是一个处理念念路。国产厂商长鑫存储已率先破局,DDR5已毕量产,其价钱比国外同类产物低15%-20%。换用国产内存,相同容量立省两成,专业赛事推荐平台从源泉上缓解了资本压力。
低比特时期则指向另一条旅途,不在“买内存”上省钱,而是在“用内存”上极致压缩。厂商无需堆砌更多内存,就能让手机跑起参数目翻倍的模子。限制是,用户既能感知AI体验升级,厂商又能已毕降本。这恰是本年行业一霎有趣低比特模子的根底原因,跳出学术探索范围,低比特模子改日可能成为化解端侧AI买卖错愕的那把钥匙。
在此基础上,面壁智能填补了国产低比特大模子市集的空缺。其BitCPM-CANN是首个在昇腾上端到端,原生完成检会的1.58-bit极低比特大模子,从算子、算法到检会框架全是国产。这讲授了国产算力平台不仅能训,还能训出全国滥觞的极低比特模子。
国产NPU阵营也第一次领有我方的1.58-Bit低比特检会栈,无需再绕谈CUDA考证、迁徙。一朝作念完,便是基础步地级的千里淀。之后统共面向昇腾的低比特检会,齐将确立在消亡套底座之上。最终限制浮现,全体显存节能约6倍,推理速率快了2到4倍。

李宇轩先容,在适配华为昇腾、激动低比特检会过程中,中枢卡点主要齐集在软件生态与工程调优层面。
在软件生态上,华为昇腾的编程门槛较高、老到其用具链的开辟者较少,尤其在长高下文复古方面有欠缺,面壁智能团队为此耗尽了多数调试时辰。
低比特检会自身也存在诸多工程难点。淌若量化器选错,模子成果会断崖式下跌。检会历程需要抽象调优,必须先作念量化感知检会让模子参加厚实经管态,再引入蒸馏,这个“甘好意思点”需要多数实验智力找到。低位宽模子在某些基础智商上容易退化,需要针对性补数据,用更耐烦的方式准备检会集。
参考面壁智能AI Infra团队的训戒,在既有GPU训戒积贮的前提下,跑通昇腾全链路仍需三玉成一个多月,更大模子适配时辰会更长。
这次BitCPM-CANN将多种数据以可复现的方式开源。
“像OpenAI和DeepSeek,推动全行业作念强化学习一样,咱们也但愿向行业讲授,在国产芯片作念极低比特检会一样可行。”
生态议价权
开云kaiyun(中国)体育官网昔时,模子厂商、芯片厂商与末端厂商各利己战。
模子在英伟达上检会,芯片厂商只管卖算力,末端厂商认真集成。但在端侧AI时间,这条显露的链条正在无极,而低比特时期,正成为荟萃三方的中枢纽带。
对模子厂商而言,低比特时期是中枢竞争力。谁能拿出更小、更快、智商保留率更高的模子,谁就能赢得末端厂商的订单。面壁智能开源BitCPM-CANN模子,现实上便是试图确立“低比特模子的措施”,以蛊惑芯片和末端厂商主动围绕其生态进行适配。
对芯片厂商来说,硬件已先行一步。高通骁龙8 Gen 4等旗舰芯片已原生复古2-bit推理。但硬件跑起来,缺的是高质地的低比特模子。面壁智能这么的模子厂商刚巧补上了供给侧的空档,让芯片厂商的硬件智商确切有了用武之地。两边深度合作,如面壁智能与华为昇腾,共同优化算子、校准量化参数,造成软硬一体的护城河。
站在末端厂商角度,低比特模子成功决定了产物的AI体验与资本结构。手机厂商不再仅仅采购芯片、预装模子,而是需要与模子厂商统一调优,以至定制专属模子。这种深度绑定,使得末端厂商一朝采选合作方,就难以简陋切换,生态锁定当然造成。
模子公司与末端厂商的合作,以至潜入到了检会阶段。面壁智能对低比特模子智商耗损的买卖化处理,便是一个很好的例证。
用户在手机、汽车上确切高频使用的,是文本追想、语音助手、信息检索这些功能,而不是写代码或解高级数学题。那些冷门智商,绝大多数用户一年也偶然用上一次。
面壁智能恰是收拢了这少量,通事后检会,把低比特模子那3%-5%的智商耗损,齐集到了这些低频功能上。限制便是中枢场景的精度近乎完满保留,用户齐全嗅觉不到体验下跌,而厂商的资本却实实在在地降了下来。
现阶段,能够提供厚实、高效、易部署的低比特模子的公司,将在端侧AI生态中占据中枢生态位。因为它既是算法提供者,亦然芯片优化伙伴,照旧末端厂商的AI智商外包方。这种多重身份带来的议价智商和生态影响力,远超传统“卖模子授权”的买卖模式。

当今端侧主流的3B-8B模子,智商约莫十分于小学生或初中生,能回话学问问题、作念简陋推理,但面临复杂逻辑、长高下文、专科领域知识时容易出错。60B模子则齐全不同,端侧AI将具备解数学竞赛题、分析法律晓谕、解读金融报表等专科智商。
当60B模子齐全运行在手机土产货时,很多蓝本必须依赖云霄的重担务将变得即时、奥秘与弥远可用。从原来设定闹钟、查天气升级为蓄意旅行道路、比价购物;勤俭单补全函数,到生成完满模块、调试bug;从写标题、案牍,到能写完满敷陈等。而且上述统共动作,不联网、不上传数据、零蔓延。
这背后是低比特时期、国产算力与端侧芯片的交织。算法让模子变小,芯片让模子跑快,内存让它装得下。当这三条弧线同期高出临界点,端侧AI的基建就搭建完成了。
一朝端侧AI基建就位2026世界杯赛事竞猜中国官网,超等应用简略也不就再远处了。